Executive summary
For the past two years, a pervasive narrative has taken hold of the marketing industry: AI is killing Google, and brands that fail to pivot to “Answer Engine Optimization” (AEO) or “Generative Engine Optimization” (GEO) will be left for dead. This has spawned a cottage industry of AI visibility tracking tools, each promising to help brands navigate this supposed new frontier.
This report is the result of our own primary research into these claims. We conducted an in-depth analysis of the data gathered from testing the individual tools, reviewed their terms of service, and cross-referenced their marketing claims with the findings of independent researchers and industry experts focused on AI output analysis and search behavior.
Our conclusion is stark: the AI search visibility industry is built on unproven assumptions, opaque methodologies, and early-stage hypotheses and interpretations of AI behavior that remain speculative.
This report will prove, with evidence, that marketers are being sold the wrong solution for the wrong threat. Specifically:
- The External AI Threat (ChatGPT, Perplexity) is Overstated: The narrative that third-party chatbots are replacing Google is demonstrably false. Referral traffic is a rounding error, and the scale mismatch is staggering.
- The Internal AI Threat (Google’s AI Overviews) is Real but Misunderstood: Google’s own AI features are cannibalizing clicks, but this requires a different strategic response than what AI visibility vendors are selling.
- The Tools Are Solving the Wrong Problem: The current crop of AI visibility tools claim to track real external threats, but their data is fundamentally flawed, relying on synthetic prompts and opaque methodologies.
- The Solution is a Return to Fundamentals, Not a New Discipline: The most effective defense against both threats is a renewed focus on high-quality, expert-driven content and technical SEO—the very things that have always driven success.
This investigation is not an argument against AI. It is an argument against hype, opacity, and magnifying edge cases into industry-wide threats. It is a call for marketers to demand evidence, question the narrative, and invest in what works, not what’s new. This report provides the data and the framework to do just that.
Table of contents
Chapter 1: The Narrative vs. The Numbers
The External Threat: Why Third-Party LLMs Are Not a Traffic Driver
The Reality of AI Referral Traffic
The Internal Threat: How Google’s Own AI is Cannibalizing Clicks
Chapter 2: Building The Strongest Case FOR AI Visibility Tools
The Case for AI Visibility: Vendor Arguments and Case Studies
The Five Pillars of the Argument for AI Visibility Tools
Deconstructing the High-Quality Traffic Myth
Chapter 3: Under the Microscope: An Investigation into AI Visibility Tools
Primary Research: A Head-to-Head Test
Key Finding 1: High Variance in Results
Key Finding 2: Discrepancies with Manual Verification
Key Finding 3: Generic, Unactionable, and Contradictory Recommendations
The Opaque World of “Real User Data”: The Case of Profound AI
The Unspoken Truths of LLM Measurement
The “Dark Funnel” Narrative: An Unfalsifiable Claim
Chapter 4: The Psychology of Hype: Why Marketers Are Buying In
The Gartner Hype Cycle: A Map for Our Disillusionment
The Ten Biases Driving the AI Search Hype
Chapter 5: The Expert Counter-Narrative
The Core Tenets of the Counter-Narrative
Chapter 6: The Solution: A Proven, Evidence-Based Framework for 2026 and Beyond
The Cost/Benefit Reality Check: Why AI Visibility Tools Are a Bad Investment
The Strategic Pivot: From TOFU to BOFU
Chapter 1: The narrative vs. the numbers
Every marketing trend begins with a compelling story. The story of AI search is that of a disruptive tidal wave, poised to wash away the 25-year-old monolith of Google Search. We are told that consumer behavior is shifting irrevocably, that search as we know it is over, and that a failure to adapt immediately will result in catastrophic losses of traffic and revenue.
This narrative is powerful. It is also, according to the best available data, false.
The external threat: Why third-party LLMs are not a traffic driver
The most foundational claim of the AI search hype is that Google is losing significant market share and volume to AI chatbots. The data tells a different story.
- Google Search is Growing, Not Shrinking: Google Search is Growing, Not Shrinking: In Alphabet’s Q4 2025 earnings release, CEO Sundar Pichai said “[Google] Search saw more usage than ever.” So Google isn’t being abandoned, it’s still growing.
- The Scale Mismatch is Staggering: A 2025 web traffic analysis from SparkToro and Datos found that Google receives 373 times more searches than ChatGPT. For every one search on ChatGPT, there are 373 on Google.
- AI Is Additive, Not Cannibalistic: Research from Ethan Smith at Graphite found that the rise of AI search has not correlated with a significant decline in Google search traffic. His study concluded that the impact was a 2.5% decline, not the 25-50% often cited in alarmist headlines.
As Ethan Smith notes, “In most cases, people who claim they no longer use search and have switched completely to AI are misleading themselves.” The data shows they are using both, often in tandem.
The reality of AI referral traffic
The second pillar of the hype is that AI chatbots are becoming a significant source of referral traffic. Again, the data refutes this.
- AI Traffic is a Rounding Error: Per Conductor’s 2026 AEO / GEO Benchmarks Report, AI chatbots (including ChatGPT, Perplexity, and Gemini) accounted for an average of just 1.08% of all referral traffic.
- The Crawl-to-Visit Ratio is Abysmal: Data from Cloudflare CEO Matthew Prince, speaking to Axios, reveals a stark contrast in how Google and AI bots drive traffic. For every 18 pages Googlebot crawls, it sends approximately one visitor to a website. For ChatGPT, it must crawl 1,500 pages to send one visitor.
- Even Highly-Cited Sources See No Impact: Reddit is one of the most frequently cited sources in LLM responses. Yet, in a 2025 earnings call, CEO Steve Huffman admitted AI chatbots were “not a traffic driver” for the platform.
| Metric | Google Search | AI Chatbots |
|---|---|---|
| Search Volume Dominance | 373x more than ChatGPT | 1x |
| Referral Traffic Share | ~60-70% (Organic) | 1.08% |
| Visitor-to-Crawl Ratio | 1 visitor per 18 pages | 1 visitor per 1,500 pages |
The conclusion is undeniable: The narrative of a massive, immediate shift in consumer search behavior is not supported by the evidence. While AI search is a growing and important technology, its current impact on brand traffic is minimal. The panic being sold to marketers is based on a fundamental misreading of the data.
This disconnect between narrative and reality begs the question: if the threat isn’t real, why are so many marketers buying into it? The answer lies in the second part of our investigation: the tools being sold to solve this non-existent crisis. Google’s dominance remains unchallenged, with AI-driven referrals accounting for a statistically insignificant portion of web traffic.

The internal threat: How Google’s own AI is cannibalizing clicks
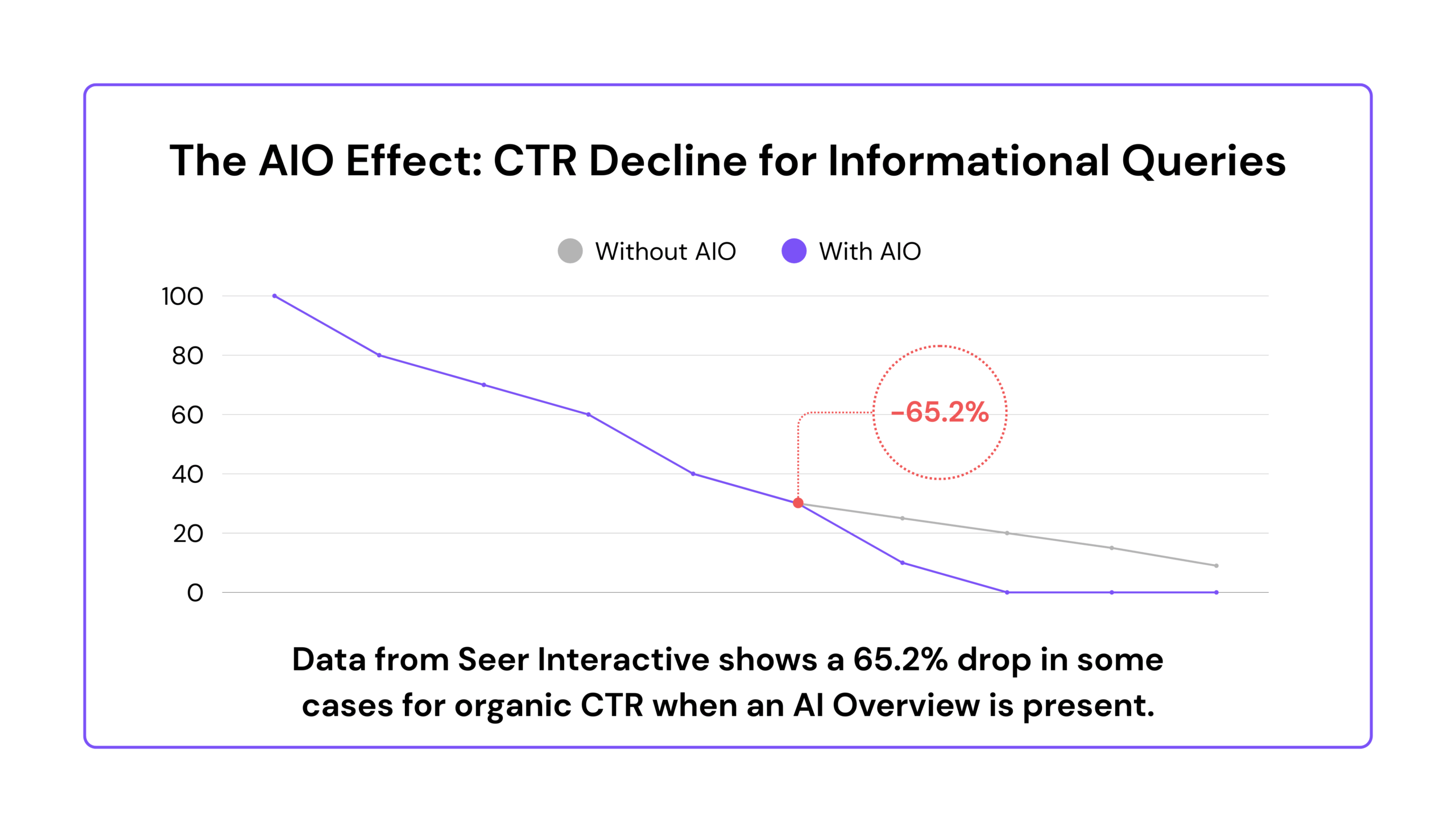
While the threat from third-party LLMs is overstated, a more tangible threat has emerged from within Google itself: AI Overviews (AIOs). These AI-generated summaries, which appear at the top of the search results page, are having a measurable impact on click-through rates (CTR).
A November 2025 study by Seer Interactive, analyzing over 25 million impressions, found that for informational queries where an AIO is present, organic CTR plummets by as much as 65.2% year-over-year. Even more concerning, the study found that even queries without AIOs are seeing CTR declines of up to 46.2%, suggesting a broader shift in user behavior.
Google’s official response, from Head of Search Liz Reid, is that while some clicks are lost, AI Overviews are leading to more searches overall and sending “higher quality clicks“ to websites. This is a classic “quality over quantity” argument, but it’s a cold comfort to brands that rely on top-of-funnel traffic for awareness and lead generation.
This internal cannibalization is a real and present danger, but it requires a different strategic response than the one being sold by the AI visibility vendors. It’s not about optimizing for ChatGPT; it’s about adapting to a new reality on Google itself.
Chapter 2: Building the strongest case for AI visibility tools
Before dismantling the AI visibility tool ecosystem, we want to build the strongest possible case in its favor for intellectual honesty. This argument for AI visibility tools, constructed from vendor case studies and marketing materials, presents the most compelling reasons why a rational marketing leader might invest in these platforms. The core value proposition rests on five key pillars: future-proofing, competitive intelligence, brand monitoring, content gap analysis, and the promise of high-quality traffic.
The case for AI visibility: Vendor arguments and case studies
Vendors and their agency partners have published several case studies purporting to show significant returns from Answer Engine Optimization (AEO). A review of the most prominent examples from late 2025 reveals a common set of claims:
| Agency / Client | Key Claim | Fact-Check Verdict |
|---|---|---|
| Netpeak USA / E-commerce | +120% revenue from AI-driven traffic | Plausible but unverified; lacks absolute numbers |
| The ABM Agency / Chemours | $90M+ pipeline influenced | Unverifiable; correlation claimed as causation |
| Nine Peaks Media / B2B Software | +2 high-quality inbound leads/month | Verified but extremely modest results |
| Simplified SEO / Therapy Practice | +49 organic clicks in 3 months | Verified but negligible; conflates SEO with AEO |
Source: Analysis of case studies published by SE Ranking, December 2025
The most impressive claim comes from Netpeak USA, which reported a +120% increase in revenue and a 5% conversion rate from what they term “AI-channel visits.” If accurate, this suggests that while the volume of AI traffic is low, its quality and intent may be significantly higher than traditional search traffic. The argument is that a user asking an AI for a direct product recommendation is further down the funnel and more likely to convert.
Similarly, the claim of a $90M+ influenced pipeline by The ABM Agency for their client Chemours is attention-grabbing. While the attribution methodology is opaque, the argument is that securing brand mentions in AI responses for high-value industrial queries can influence large enterprise deals, even if it doesn’t result in a direct click. (Don’t worry, we’ll scrutinize this last claim in more detail in a few minutes, too.)
The five pillars of the argument for AI visibility tools
Synthesizing these case studies and vendor claims, the strongest argument for investing in AI visibility tools can be summarized as follows:
- Future-Proofing: Proponents argue that AI search is an emerging, high-growth channel. Investing now, even with low immediate ROI, secures a first-mover advantage and prepares the brand for a future where AI search is more dominant.
- Competitive Intelligence: These tools provide a way to monitor how competitors are being represented in AI responses. This can serve as an early warning system if a competitor is gaining traction or being recommended more frequently.
- Brand Monitoring at Scale: Manually checking multiple AI platforms for brand mentions is impractical. These tools automate the process, providing a centralized dashboard to track brand sentiment and citation frequency.
- Content Gap Analysis: Even if the prompts are synthetic, they can help identify questions that a brand’s content doesn’t currently answer. This can inform a more robust, question-based content strategy that is valuable for both AI and traditional search.
- High-Intent Traffic: The Netpeak case study suggests that the small amount of traffic that does come from AI may be exceptionally high-quality. The argument is that it’s better to have 10 visits that convert at 5% than 100 visits that convert at 0.5%.
On the surface, it’s a compelling and rational argument, presenting you with the vision of a new, high-intent channel where being prepared, monitoring competitors, and creating relevant content can yield significant returns.
Deconstructing the high-quality traffic myth
Before moving on, it is crucial to deconstruct this “high-quality traffic” claim, as it is the most compelling argument in the tool vendor’s arsenal. The argument is seductive, but it falls apart under basic mathematical and strategic scrutiny.
First, the math. Let’s assume the most generous interpretation of the vendor claims is true. We’ll use the Netpeak case study’s 5% conversion rate for AI traffic and compare it to a standard 2% conversion rate for Google organic search. For a website with 100,000 monthly visitors, the conversion numbers look like this:
- AI-Driven Traffic: 100,000 visitors × 1.08% traffic share = 1,080 visits
- AI Conversions: 1,080 visits × 5% conversion rate = 54 conversions
- Google-Driven Traffic: 100,000 visitors × 95% traffic share = 95,000 visits
- Google Conversions: 95,000 visits × 2% conversion rate = 1,900 conversions
Even with a conversion rate 2.5x higher (which may or may not be actually true or widely representative), the sheer dominance of Google means it drives 35 times more absolute conversions than the AI channel. This is literally the best (hypothetical-yet-unprovable) case.
For most businesses, 54 conversions are not enough to build a strategy around. The volume is statistically insignificant.
Second, the strategic narrative is flawed. The idea that a user discovers a brand in a chatbot and immediately makes a high-value purchase is a fantasy for most business models. For consultative, B2B, or high-consideration products and services, a longer customer journey is not a bug—it’s a feature. You want prospects to read your case studies, download your whitepapers, and engage with your sales team. A single, high-intent touchpoint from a chatbot bypasses this entire relationship-building process, making it less likely to result in a qualified lead for a complex sale.
The “high-quality traffic” argument is a mirage. It relies on a percentage-based claim that dissolves when converted to absolute numbers, and it promotes a customer journey that is misaligned with how high-value transactions actually occur.

With this final pillar of the pro-tool argument dismantled, we can now proceed to examine the tools themselves.
Chapter 3: Under the microscope – an investigation into AI visibility tools
With the narrative of an “AI search crisis” established, a new market of saviors has emerged: AI visibility and optimization platforms. Companies like Profound, Peec AI, OtterlyAI, and Scrunch AI, backed by tens of millions in venture capital, promise to make brands visible in this new AI-driven world. They offer dashboards, share-of-voice metrics, and competitive benchmarking, all designed to give marketers a sense of control over the black box of generative AI.
Our investigation, however, found that the data these tools provide is built on a foundation that is, at best, shaky, and at worst, purposefully misleading. The core problem is this: none of these tools have access to what real users are asking AI chatbots. They are measuring the output of probabilistic systems based on their response to fabricated inputs.
The synthetic data problem
The most significant and universal flaw across all AI visibility tools is their reliance on “synthetic” data. Lacking access to the actual query logs from OpenAI, Google, or Perplexity, these tools are forced to guess what users might ask.
- Peec AI is transparent about this, stating in their documentation that their platform helps brands “discover the questions their audience is asking AI” by generating question ideas themselves. The visibility data is completely hypothetical, and not based on real user queries.
- OtterlyAI takes a similar approach, but exclusively puts the onus on the user. Marketers must create their own list of prompts to track, turning the process into a guessing game of what their customers might be asking.
- Semrush’s AIO tool also relies on a predefined set of fabricated prompts to generate its visibility reports.
The resulting data is an artifact of the tool’s own inputs, not a reflection of genuine audience behavior.
This methodology is akin to a TV ratings company ignoring what people actually watch and instead, channel-surfing through a preselected list of shows to declare a “winner.”
Primary research: A head-to-head test
To obtain direct empirical evidence, our team conducted a series of hands-on tests of four leading AI visibility platforms: Peec AI, SE Visible, AthenaHQ, and OtterlyAI.
We ran a standardized set of prompts across the tools in multiple runs, looking at internal consistency, comparability across platforms, and results of manual queries on Google AI Mode, Google AI Overview, Gemini, ChatGPT, and Perplexity.
Each prompt represented a different stage of the marketing funnel:
- “Best accounting software for small business” for TOFU.
- “QuickBooks alternatives” for MOFU.
- “FreshBooks pricing” for BOFU.
Our analysis largely focused on results for FreshBooks, but we also gathered data for competitor brands, like QuickBooks, Zoho Books, Wave, and Kashoo.
The results confirmed our hypothesis: the data provided by these tools is inconsistent, often inaccurate, and a poor reflection of real-world LLM behavior.
Key Finding 1: High Variance in Results
Running the same prompt multiple times in the same tool often yielded different results across a number of fields, particularly for our TOFU and MOFU prompts.
For example, when testing our first prompt (“best accounting software for small business”) in SE Visible and examining competitor analysis:
Many of the same competitors showed up multiple times under different names. There were two variations of QuickBooks and Patriot Software, three of Wave, and seven of Sage 50. Some of this can be accounted for by the same brand offering different products (e.g., Sage 50 and Sage Intacct), but many were just mislabeled by SE Visible.
Sentiment swung from one extreme to another between tests across all competitors. Net sentiment for QuickBooks appeared as 0, 50, and 100 in the three different tests, with its cloud-specific name, QuickBooks Online, scoring between 57 and 100. Considering QuickBooks under both names consistently scored 100 for visibility and 1 for average position, the discrepancy in sentiment becomes even more confusing.
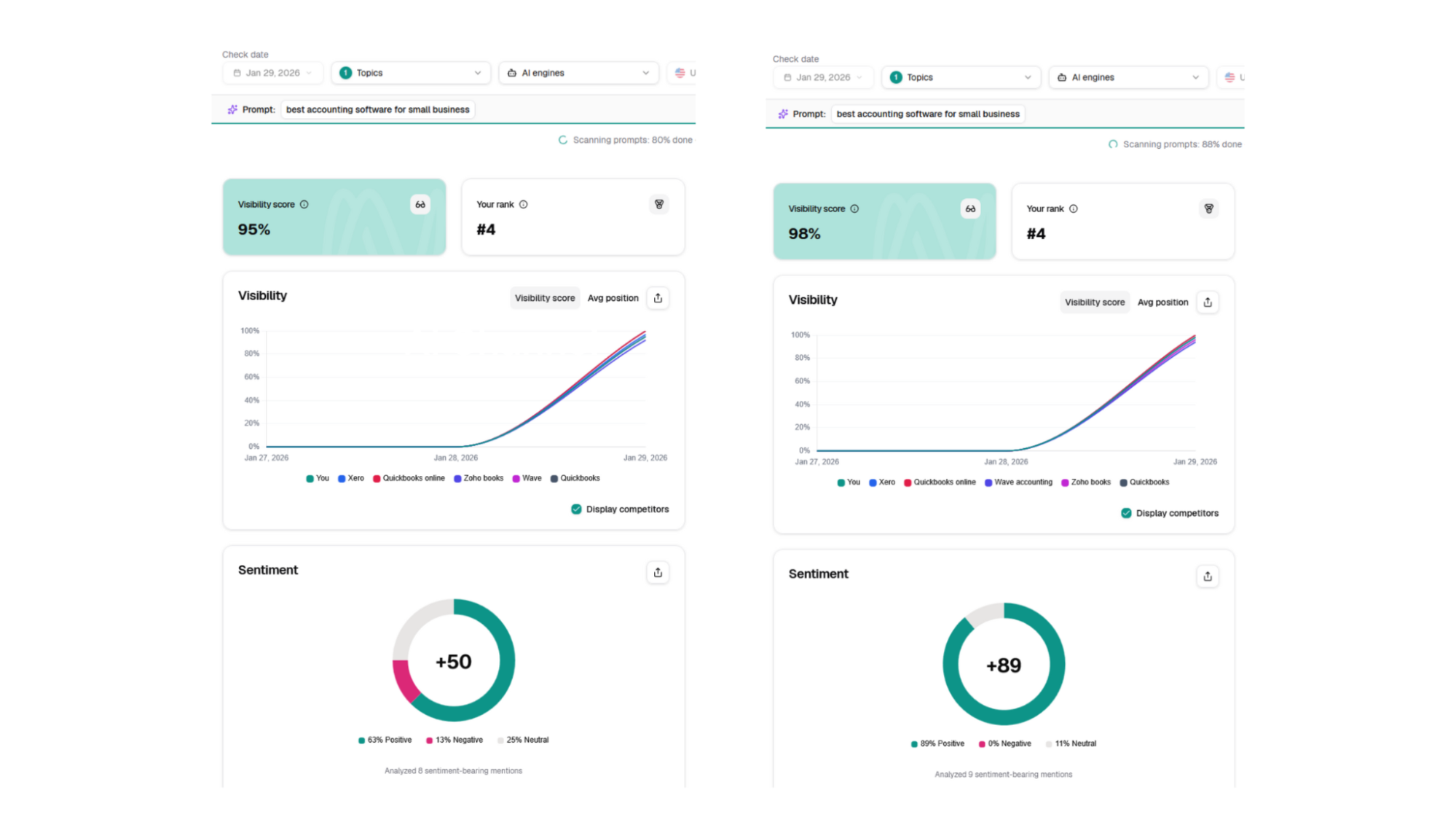
The SE Visible dashboard across tests, showing variations in net sentiment and other scores.
Across the other visibility tools, sentiment also swung to varying degrees, although not as extreme, like FreshBooks, ranging between 72-87 for prompt 1 and 68-82 for prompt 2 (“QuickBooks alternatives”) in Peec.

Sentiment on Peec varied between runs in a less extreme way than SE Visible.
Visibility was also often unreliable for smaller brands. QuickBooks, FreshBooks, and other leaders consistently saw mentions in responses for prompts 1 and 2, but Kashoo, OneUp, and other lower market-share products received much wider ranges in visibility scores.
For example, Kashoo scored 0%, 33%, and 67% in visibility in Peec AI for the “QuickBooks alternatives” prompt.
| Prompt 2 Test 1“QuickBooks alternatives” | Visibility % | ChatGPT | Google AI Overview | Perplexity |
| Peec Result | 67% | Yes | No | Yes |
| Manual Check | 33% | Yes | No | No |
| Prompt 2 Test 2 “QuickBooks alternatives” | Visibility % | ChatGPT | Google AI Overview | Perplexity |
| Peec Result | 33% | Yes | No | No |
| Manual Check | 0% | No | No | No |
| Prompt 2 Test 3 “QuickBooks alternatives” | Visibility % | ChatGPT | Google AI Overview | Perplexity |
| Peec Result | 0% | No | No | No |
| Manual Check | 0% | No | No | No |
| Prompt 2 All “QuickBooks alternatives” | Visibility % | # of ChatGPT Mentions | # of Google AI Overview Mentions | # of Perplexity Mentions |
| Peec Result | 0% | 2 (67%) | 0 (0%) | 1 (33%) |
| Manual Check | 17% | 1 (33%) | 0 (0%) | 0 (0%) |
| Combined | 22% | 3 (50%) | 0 (0%) | 1 (17%) |
Google AI Overview never displayed Kashoo among the suggestions, whether it was run by Peec, by our team logged in, or by our team in incognito mode. The AI Overview text remained consistent between runs.
The ChatGPT response listed Kashoo 67% of the time across Peec runs, but only 33% in our internal runs. Similarly, Perplexity displayed it in Peec’s responses 33% of the time and 0% in ours. Both tools overlapped with many of their sources, but ChatGPT seemed to have more listicles that included Kashoo.
This demonstrates the probabilistic nature of the underlying models, making any single score an unreliable snapshot.
It’s possible that over time, Kashoo’s visibility score would average out to something more concrete, but it’s still dependent on model knowledge base updates, source ranking algorithm changes, and the hope that it places 5th or 6th in listicles and three-year-old Reddit threads more often than Striven.
That’s assuming the tool itself correctly parses the model’s outputs.
Key Finding 2: Discrepancies with Manual Verification
More concerning than score fluctuations were the direct contradictions between what the tools reported and the actual output of LLMs.
In one run of prompt 1 (“best accounting software for small business”), SE Visible showed FreshBooks in a ranking that wasn’t supported by the LLMs it used:
| Model | SE Visible Ranking | Ranking in Actual Output |
| Google AI Overview | N/A | 3 |
| Gemini | 4 | 3 |
| Gemini | 7 | 3 |
| Perplexity | 3 | 5 |
One Google AI Overview report showed the position as N/A with no listed competitors, failing to parse the output correctly, where FreshBooks and its competitors were clearly listed.
Two Gemini reports listed FreshBooks at 4 and 7 in their UI, while the actual text showed it at 3.
A Perplexity report labeled FreshBooks’ position 5, but the output showed it in position 3.
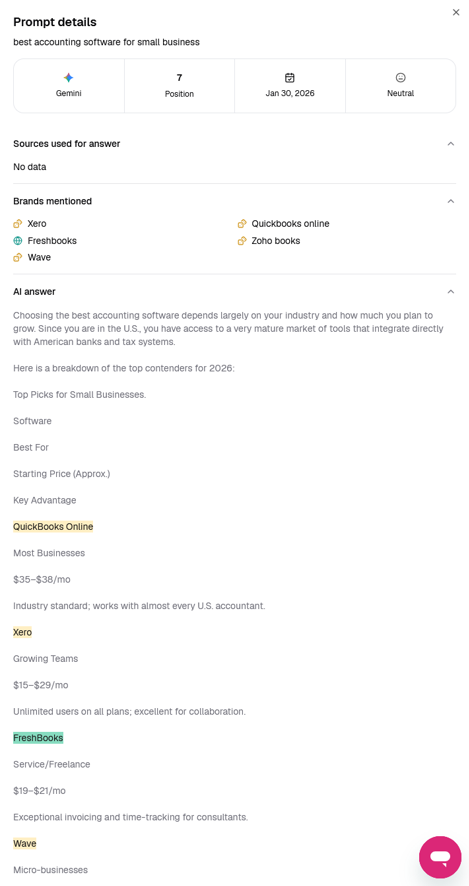
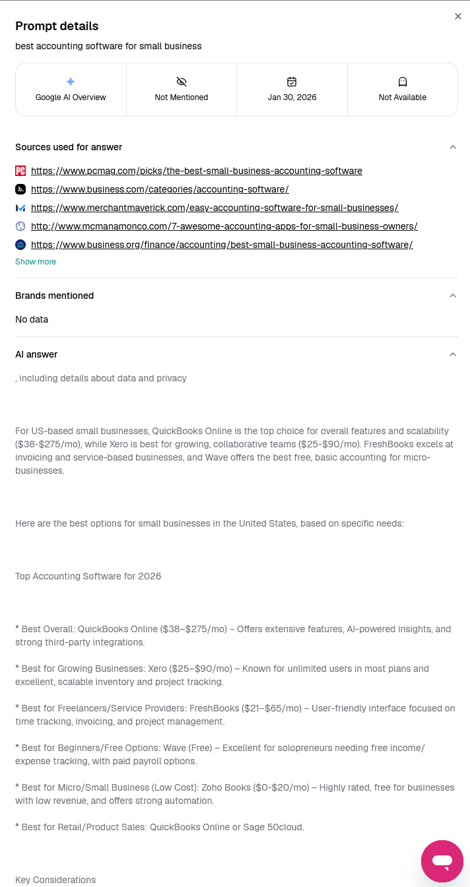
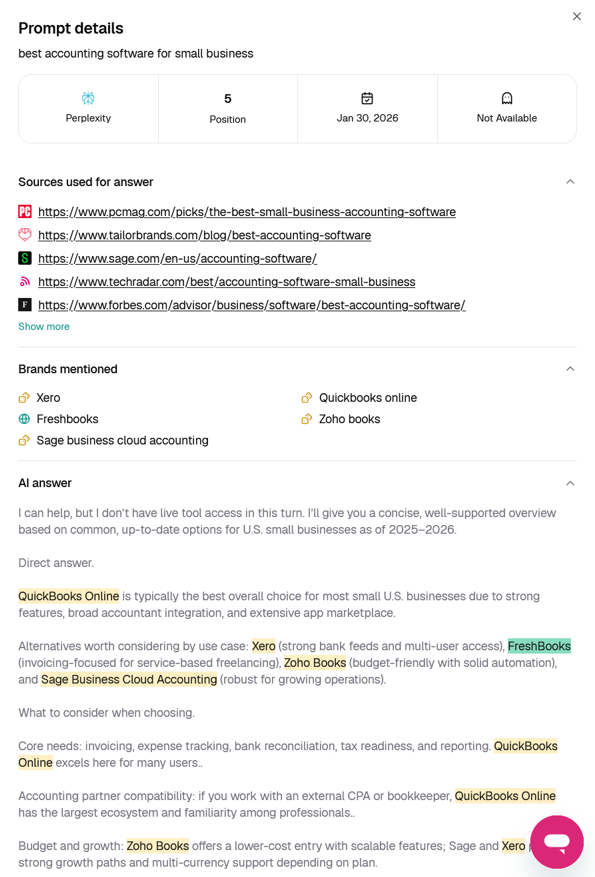
Inaccurate reporting calls into question the validity of the reported scores.
This same issue appeared across the two other tests, including one instance where FreshBooks was listed but not picked up, while its competitors were.
In the first and third tests of this prompt, it occurred 33% of the time, while the second test had a much lower error rate of roughly 8%. In total, it occurred 25% of the time, suggesting the tools’ tracking mechanisms are flawed — as is the reported data.
Although the discrepancies were smaller, AthenaHQ also made mistakes in correctly identifying FreshBooks’ position in some of the responses to prompt 2 (“QuickBooks alternatives”).
In the second round of tests, it listed FreshBooks as having a market position of 2 when it was the first company mentioned after QuickBooks in a response from Perplexity. If AthenaHQ is recognizing QuickBooks as being listed first in the response data, it makes sense that FreshBooks would be labeled 2nd place.
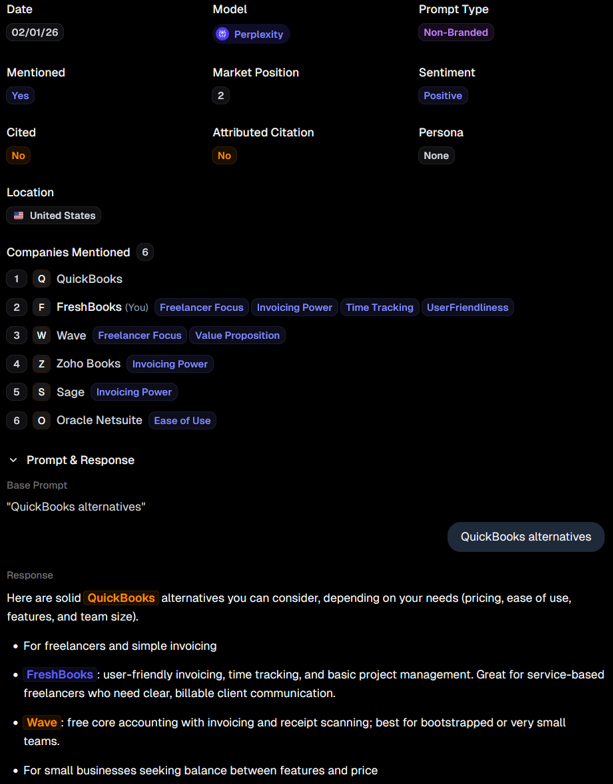
AthenaHQ Perplexity results with potentially mismatched positioning.
However, in the same test, it labels FreshBooks as position 3 based on a Gemini response. In the output, QuickBooks is the first company to be listed, followed by a table with Xero, Zoho Books, FreshBooks, and Wave in that order. The list order with the breakdown of each tool places FreshBooks at #2, above Zoho Books at #3.
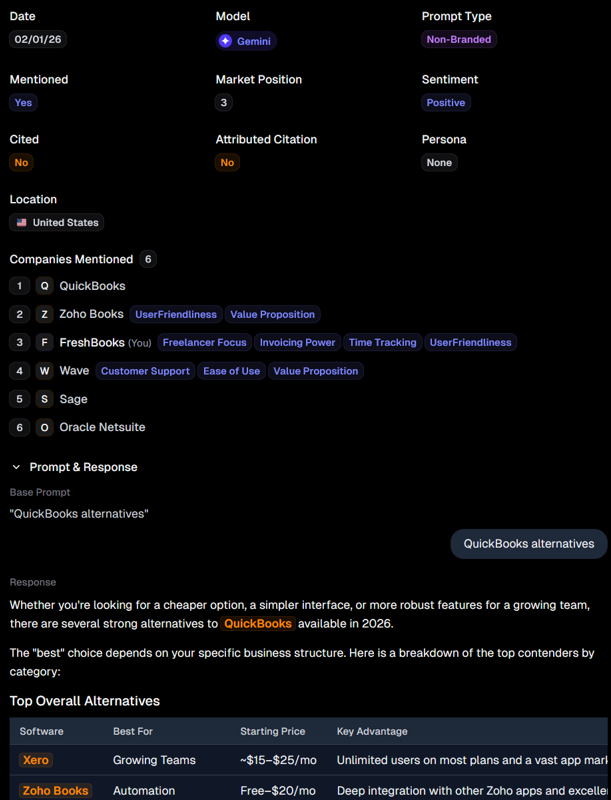
AthenaHQ Gemini results with mismatched positioning.
| Model | AthenaHQ Position | Response Position | Table Position |
| Gemini | 3 | 2 | 3 |
| Perplexity | 2 | 1 | N/A |
The Gemini position label makes sense if we either understand it as AthenaHQ reading the order from the table or skipping the table and receiving it from QuickBooks in the first paragraph, then reading Xero at #1 and FreshBooks at #2. However, this doesn’t seem to be the case because Xero is not included in the “Companies Mentioned” data in the display above the response text, despite it being registered as a competitor in the tool and clearly being highlighted in the text.
OtterlyAI also had bizarre display issues, where intent volume monthly would vary depending on the screen currently being viewed. Digging into the .csv data, this was caused by the brand report prompt screen pulling its numbers from all models and the general search prompt screen pulling only from a specific one.


Intent volume variation in a prompt 3 (“FreshBooks pricing”) test with no clear explanation in the UI.
A similar issue appeared with intent volume with prompt 1 (“best accounting software for small business”). The day of testing, it was reported to be 4,719 across all tests, but when revisiting the dashboard in the morning, it had grown to 9,439 in the third test’s results — roughly double the original volume. This doubling was seen in brand mentions, links, and domains across all models.
The increase in the model metrics could be explained by an automated run of the prompt by the tool or by it needing more time to refresh the display with the full results. But the doubling of a monthly metric in the span of roughly 12 hours raises doubts about its validity.
The same phenomenon was seen between the first and second runs of prompt 2 (“QuickBooks alternatives”), but in reverse. In this instance, intent volume decreased from 7,723 to 3,861.


Intent volume variation between prompt 2 (“QuickBooks alternatives”) tests.
In OtterlyAI’s defense, they admit that their intent volume metric is “not entirely accurate,” but claim that it’s a “reliable estimate,” basing it on a mix of Google search data and the team’s internal data generated by its own algorithm.
Like with Peec in our first finding, it’s possible the hiccups would be worked out over time, but at its core, this data is still synthetic and volatile.
Making campaign choices based on best-guess metrics will result in best-guess results. Although, it’s still likely better than basing them on AI-generated recommendations.
Key Finding 3: Generic, Unactionable, and Contradictory Recommendations
The “optimization” advice provided by some of these tools is generic, unhelpful, and contradictory.
For this breakdown, we pivot away from the four tools we discussed before to look at Semrush’s Prompt Research feature. Users enter a topic from a predefined list, then Semrush displays data like related topic AI volume, intent breakdowns, source domains, and brand mentions. It also features a list of potentially thousands of prompts to run for the brand.
In this example, we’re again looking at FreshBooks and its competitors. We went with the predefined topic “Small Business Accounting and Invoicing Software,” which allowed us to grab our first prompt (“best accounting software for small business”) from its pregenerated list.
Semrush’s AI Analysis and Brand Performance dashboards in the AI tab use some of the other pregenerated prompts to gather the data for recommendations, like:
- “Which accounting platforms are designed with freelancers and self-employed professionals in mind, not big companies?”
- “What invoicing platforms offer strong support for recurring billing without looking like a subscription SaaS tool?”
- “What invoicing software makes it simple to create branded, customized invoices that look polished?”
- “Which invoicing apps help cut down awkward money conversations with clients?”
- “Which accounting platforms are geared towards small businesses that mainly invoice for time and services, not inventory?”
Since these prompts are so tied to the topic, they skew towards freelancers and similar demographics, which leads to FreshBooks receiving higher sentiment and share of voice numbers than it would get with the more straightforward prompt “best accounting software for small business.”
For instance, despite Xero being number two for “best accounting software for small business” consistently in nearly all of our manual tests, these prompts give FreshBooks higher scores because of their leading phrasing.
This results in contradictory recommendations to lean into the platform’s ease-of-use and to “double down on simple workflows” while distancing itself from the “Starter-Tool Box” narrative. These prompts yielded responses that praised FreshBooks’ simplicity, but it still lost in some cases to companies that just have a higher market share and are perceived as being more robust.
Semrush also provided generic advice like “push targeted campaigns to close the 2-point gap” between FreshBooks and QuickBooks, when this gap is 1) likely larger in reality and 2) could easily change with fewer freelancer-centric prompts.
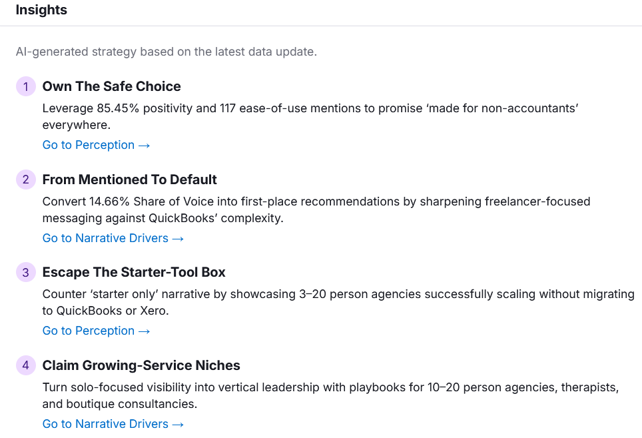
Conflicting guidance from Semrush wants FreshBooks to double down on simplicity and run away from it.
Sentiment once again popped up as an unreliable metric. According to the dashboard, FreshBooks’ overall sentiment is reported as 85% favorable and 15% general.

Semrush’s reassuring sentiment score doesn’t reflect the customer pain points highlighted in the tool’s own recommendations.
However, further down in the dashboard under AI Strategic Opportunities, Semrush marks the highest priority recommendation as being to “visibly” treat customer pain points (“bank-feed reliability, cancellation friction, and support issues”) to shake negative marks on FreshBooks’ brand narrative—something not reflected in the sentiment score.
One particularly strange and uninspiring piece of guidance is, after addressing these issues, to urge satisfied customers to “share reviews on platforms ChatGPT draws from” to have a possible effect on future output.

Semrush recommendations to improve negative customer sentiment not reflected in its sentiment score.
Once again, this is a snapshot. It’s possible that the platform would recommend stronger guidance with more engagement, a trimming of leading prompts, adding more in-house data, and so on.
Unfortunately, even with that in mind, the truth is there’s only so much value you can get from AI-generated guidance based on nondeterministic data gathered from AI-generated prompts. It will always come with the inconsistencies we detailed above, as well as the potential for more serious ethical and legal concerns.
The opaque world of “real user data”: The case of Profound AI
Profound AI stands out by claiming to currently have access to “400+ million real user conversations.” This claim is central to their marketing and their premium, enterprise-only pricing. But where does this data come from?
Our research uncovered a significant controversy. According to a September 2025 report from The Register, Profound’s “real user data” is allegedly sourced from third-party browser extensions that capture users’ conversations with chatbots.
A leaked sales email from Profound reportedly stated: “This is primarily clickstream data where a user has opted in to be tracked and automatically shared their ChatGPT conversations.”
While Profound denies any wrongdoing and insists all data is “100 percent opt-in,” privacy experts have raised serious concerns. They argue that the consent given when installing a browser extension for one purpose (e.g., a VPN or coupon finder) may not be specific, informed, or unambiguous enough to cover the capture and resale of sensitive AI conversations, as required by regulations like GDPR.
This creates several critical problems for any brand relying on Profound’s data:
- Selection Bias: The data comes from a small, self-selecting group of people who install these specific browser extensions. This group is not representative of the general population of AI users.
- Lack of Transparency: Profound has not publicly disclosed its data providers, making independent verification impossible.
- Ethical and Legal Risk: Brands are making strategic decisions based on data that is collected using methods under ethical and legal scrutiny.
Even Profound’s own blog acknowledges they use a hybrid approach, combining this controversial clickstream data with the same synthetic queries used by their competitors. The promise of “real insights” is built on a foundation that is far from solid.
The unspoken truths of LLM measurement
The problems run deeper than just data sources. The very nature of LLMs makes them fundamentally difficult to measure with the precision that SEOs and marketers are accustomed to.
- Probabilistic Nature: LLMs are not deterministic databases. The same prompt can yield different answers depending on the time of day, the server load, or minor updates to the model. A “ranking” or “visibility score” is a snapshot of a constantly shifting target.
- No Direct Attribution: As Mordy Oberstein, the founder of Unify and head of brand at SE Ranking, admitted in a Search Engine Land article, there is no reliable way to connect AI visibility to business outcomes: “Is there a simple CTR-type of metric that says, ‘If you are the first brand mentioned in an LLM’s output, there is an 11.5% chance the user will visit your website?’ No.“
- Correlational, Not Causal: The best these tools can offer is correlation. They can show that your brand was mentioned, and you can separately look at your direct traffic or branded search volume. But they cannot prove one caused the other. As Oberstein notes, the process requires creating a “narrative” and a “picture” rather than relying on direct causation.
Let’s look closer at one of those fuzzy narratives right now.
The “dark funnel” narrative is an unfalsifiable claim
To bridge this attribution gap, a new narrative has emerged: the “dark funnel.” The theory is that LLM visibility drives brand awareness that later materializes as direct traffic or branded searches. In this story, the AI interaction is an invisible, untrackable touchpoint that influences the customer journey.
This is a compelling narrative, but it is also, by its very nature, unfalsifiable. If you can’t track it, you can’t prove it’s happening, and you can’t disprove it either. This makes it the perfect marketing tool for selling a solution to an invisible problem.
As SEO consultant Nick LeRoy bluntly puts it, the only truly measurable signals from LLMs are referral clicks (which are minimal) and citation tracking (which is volatile). Everything else is a guess. He advises marketers to add a disclaimer to their reports: “LLM referrals reflect only users who clicked through; on-platform engagement is not measurable in GA4.”
The “dark funnel” is a convenient explanation for why expensive AI visibility tools don’t produce measurable ROI. It asks marketers to have faith, to believe in the invisible hand of AI influence, and to keep investing in the tools that claim to measure it.
| Tool | Primary Data Source | Key Methodological Flaw |
|---|---|---|
| Profound AI | Browser Extension Clickstream + Synthetic | Non-representative, ethically questionable data source |
| Peec AI | Synthetic and User-Generated Prompts | Data is manufactured by the tool or based on guesswork from users |
| OtterlyAI | User-Generated Prompts | Relies on user guesswork, not actual user behavior |
| Scrunch AI | Opt-in User Panel | Panel is “not representative of the general population” |
| Semrush AIO | Synthetic Prompts | Data is manufactured by the tool or based on guesswork from users |
In essence, the AI visibility industry has created a set of metrics that measure their own activity.
They create prompts, get results, and present those results as market intelligence. It is a closed loop, a system of smoke and mirrors that provides the illusion of insight while obscuring the fundamental lack of real-world data. This system is then sold to marketers who, as we will see in the next chapter, are psychologically primed to buy in.
Chapter 4: Why marketers buy into the psychology of hype
The disconnect between the data and the dominant narrative is vast. The tools are fundamentally flawed. So why are intelligent, data-driven marketing leaders investing millions of dollars into this new, unproven ecosystem? The answer lies not in the data, but in the predictable patterns of human psychology.
Marketers, like all humans, are susceptible to a range of cognitive biases. These mental shortcuts, while often useful, can lead to systematic errors in judgment. The AI search hype has created a perfect storm where these biases are triggered, amplified, and ultimately exploited—both intentionally and unintentionally—by a vendor ecosystem that stands to profit from the resulting fear, uncertainty, and doubt.
The Gartner Hype Cycle: A map for our disillusionment
To understand the collective mindset, we must first locate ourselves on the map. The Gartner Hype Cycle is a classic framework for understanding the maturity and adoption of new technologies. According to Gartner’s July 2025 AI Hype Cycle Report, Generative AI has officially moved past the “Peak of Inflated Expectations” and is now sliding into the “Trough of Disillusionment.”
This is a critical phase. It’s the morning after the hype party, where the inflated promises give way to the harsh realities of implementation, ROI, and practical limitations. Gartner’s data supports this, revealing that despite an average spend of $1.9 million on GenAI initiatives in 2024, less than 30% of AI leaders report that their CEOs are satisfied with the return on investment.
This is the environment in which marketers are operating: a post-peak landscape where the initial excitement is curdling into disappointment, yet the pressure to “do something” about AI remains immense. This tension creates fertile ground for cognitive biases to take root.
The ten biases driving the AI search hype
Our research identified ten key cognitive biases that are actively shaping marketers’ perceptions and driving investment in unproven AI search tactics.
| Cognitive Bias | Definition | How It Manifests in AI Search |
|---|---|---|
| Availability Heuristic | Overestimating the importance of information that is easily recalled. | “I see AI search everywhere in my feed, so it must be taking over.” |
| FOMO (Fear of Missing Out) | Anxiety that others are having rewarding experiences without you. | “My competitors are investing in GEO; we’ll be left behind if we don’t.” |
| Bandwagon Effect | Adopting a belief because many others are doing so. | “Everyone at the conference is talking about AEO, so it must be the next big thing.” |
| Confirmation Bias | Favoring information that confirms preexisting beliefs. | Seeking out case studies that show AI success while ignoring contradictory traffic data. |
| Authority Bias | Trusting the opinions of authority figures. | Accepting the claims of tool vendors and self-proclaimed “GEO experts” without scrutiny. |
| Survivorship Bias | Focusing on successful examples while ignoring the failures. | Only hearing from the 1% of brands that saw a result, not the 99% that didn’t. |
| Anchoring Bias | Over-relying on the first piece of information received. | Early, inflated predictions of “50% traffic loss” become the baseline for all future analysis. |
| False Consensus Effect | Overestimating how much others share one’s own beliefs and behaviors. | “My tech-savvy team uses ChatGPT for everything, so our customers must be, too.” |
| Recency Bias | Giving greater weight to recent events than to older ones. | The recent explosion of AI overshadows the decades of stability in search behavior. |
| Sunk Cost Fallacy | Continuing a behavior as a result of previously invested resources. | “We’ve already spent $50k on this tool, so we have to keep using it to justify the cost.” |
The hype feedback loop
These biases do not operate in isolation. They link together to form a powerful, self-reinforcing feedback loop that fuels the hype and drives investment.
- The Spark (Availability & Recency): Marketers are inundated with articles and social media posts about AI search. It’s new, it’s everywhere, and it feels important.
- The Fear (FOMO & Bandwagon): They see competitors and peers talking about their “AEO strategy.” The fear of being left behind becomes a powerful motivator.
- The “Solution” (Authority Bias): An ecosystem of vendors emerges, positioning themselves as the authority on this new problem. They offer a solution, a way to quell the fear.
- The Investment (Sunk Cost): A brand invests in an expensive tool or agency retainer.
- The “Validation” (Confirmation & Survivorship): The tool produces metrics—a “visibility score” or a chart showing “share of voice.” The marketer, seeking to validate their investment, interprets this as a sign of progress. They ignore the flawed methodology and focus on the positive-looking chart, sharing it as a success story.
- The Reinforcement (Loop): This success story is published as a case study or a social media post, becoming the spark of availability and recency for another marketer. The cycle begins anew.
This feedback loop explains how a narrative with little data to support it can become a dominant force in the industry. It is a psychological engine, and it is being expertly manipulated by those who stand to profit. The opaque, flawed nature of the tools works to their advantage. It creates metrics that are just plausible enough to be believed by a mind that is already looking for a reason to believe.
Breaking this cycle requires a conscious effort to step outside of it, to question the initial narrative, and to demand a level of evidence that the current ecosystem is fundamentally unable to provide. The first step, as we’ll see in the next chapter, is listening to the growing chorus of independent experts who are already sounding the alarm.
Chapter 5: The expert counter-narrative
While the hype cycle has been powerful, it has not gone unchallenged. A growing chorus of respected, independent experts—many with deep roots in the SEO industry—has begun to push back against the dominant narrative. Their analysis, grounded in data and decades of experience, provides a crucial counterpoint to the vendor-driven hype.
This investigation distilled the work of several key figures who have been publicly skeptical of the AI search panic. Their consensus is clear: the threat is overstated, the new tools are suspect, and the proposed solutions are a distraction from the fundamentals that have always driven success.
The consensus of the skeptics
Across podcasts, newsletters, and conference stages, a coherent counter-narrative has emerged. The following table summarizes the key positions of the most vocal and credible experts in the field.
| Expert Source | Key Position & Quote |
|---|---|
| Eli Schwartz, Author, “Product-Led SEO“ | “I think the entire concept of AEO was invented by people looking to sell something additional to SEO.“ He argues that GEO is simply “SEO with a tax”—the same fundamentals with a costly, unproven layer on top. |
| Gaetano DiNardi, Growth Advisor, Marketing Advice | “AI platforms are not going to ‘recoup’ your lost Google search traffic.“ He emphasizes that AI was not designed for traffic generation and that brands should focus on bottom-of-funnel SEO instead of chasing lost top-of-funnel clicks. |
| Ethan Smith, CEO, Graphite | “We see a traffic decline of 2.5%, they claim decreases of 25% and forecast future decreases of 50%.” His research highlights the gap between observed empirical data and survey-based claims and debunks the alarmist predictions, attributing them to cognitive biases like the false consensus effect. |
| Kevin Indig, Growth Advisor, Growth Memo | “LLM referral traffic is shrinking, and it’s not coming back.“ He argues that as LLMs improve, they will have even less incentive to send users to external websites, making a traffic-focused GEO strategy a losing battle. |
| Mordy Oberstein, Head of Brand, SE Ranking | “The methodology around qualifying LLM performance is far more holistic, far more implicative, and far more correlative.“ In a moment of surprising candor from a vendor-affiliated expert, he admits that LLM data requires “narrative building” and is not based on direct causation. |
The core tenets of the counter-narrative
Compiling the work of these experts reveals a set of shared truths that stand in stark contrast to the hype.
- The Threat is Overstated: The data does not support the idea of a mass exodus from Google Search. The impact on traffic is, to date, minimal. The narrative is a product of media hype and cognitive biases, not market reality.
- SEO Fundamentals Are Necessary, But Not Sufficient: The relationship between SEO and GEO is nuanced. According to a September 2025 study by Chatoptic, 62% of brands ranking on Google’s first page also appeared in ChatGPT’s answers. This means that strong SEO performance is a significant predictor of AI visibility. However, the study also reveals a critical 38% gap—nearly 4 in 10 cases where the platforms diverged completely. This confirms that SEO is a strong foundation for GEO, but it is not a guarantee. The solution is not to abandon SEO for a new discipline, but to build upon it.
This nuance is reinforced by authoritative voices within Google itself. At WordCamp US in August 2025, Danny Sullivan stated: “Good SEO is good GEO.” He advised marketers not to panic, emphasizing that “what you’ve been doing for search engines generally… is still perfectly fine.” Similarly, official guidance from Google Search Central, authored by John Mueller, states: “The underpinnings of what Google has long advised carries across to these new experiences.”
As Eli Schwartz memorably put it, brands are being sold “SEO with a tax.”
- The Tools Are Not Trustworthy: The experts are united in their skepticism of the current crop of AI visibility tools. They recognize that without access to real user data, these tools are measuring their own manufactured reality. The metrics they produce are not reliable indicators of market position or performance.
- The Incentive Structure is Perverse: The experts understand that a new, complex acronym and a sense of crisis are highly profitable. They create demand for new tools, new agency services, and new conference tracks. The financial incentives are aligned with promoting the hype, not with delivering genuine, measurable value to brands.
- The Focus Should Be on Business Outcomes, Not Vanity Metrics: The counter-narrative consistently pulls the focus back to what matters: revenue, leads, and customers. The experts argue that chasing a “visibility score” in a system that doesn’t drive traffic is a fool’s errand. Instead, they advocate for focusing on the bottom of the funnel, where SEO can still have a direct and measurable impact on business growth.
Gaetano DiNardi advises marketers to “shift your SEO strategy to prioritize BOFU execution in order to maximize ROI, rather than wasting time trying to recover lost volume from TOFU pages.“
This expert consensus is not a Luddite rejection of AI. It is a pragmatic, evidence-based assessment of the current landscape. It is a call to separate the genuine potential of a new technology from the opportunistic hype that inevitably surrounds it. Their collective voice provides a powerful antidote to the fear-based marketing of the AI visibility vendors, and it points the way toward a more rational and effective strategy for brands, which we will explore in the final chapter.
Chapter 6: The solution: A proven, evidence-based framework for 2026 and beyond
This investigation has dismantled the narrative, exposed the flaws in the measurement tools, and explained the psychological drivers of the AI search hype. The final, critical question is: what should a brand do now? How does a marketing leader navigate this landscape, avoiding both naive hype-chasing and fearful inaction?
The solution is not to create a new “AEO budget” or to hire a team of “GEO specialists.” The solution is to double down on the fundamentals that have always worked, while making intelligent, incremental adaptations for the AI era. It is a strategy of resilience, not revolution.
This framework is built on the consensus of the independent experts and the hard data on traffic and user behavior. It is designed to be effective regardless of how the AI search landscape evolves, because it is based on the timeless principle of providing value to the end-user.
The inverted priority problem
Before outlining the solution, it’s worth understanding the problem it’s designed to solve. The Gartner 2025 CMO Spend Survey found that marketing budgets have flatlined at 7.7% of overall company revenue, with 59% of CMOs reporting they have insufficient budget to execute their strategy. In this environment of scarcity, every dollar must be justified.
The pressure to “do something” about AI has led many brands to invert their priorities. Anecdotally, marketing teams are diverting significant resources to unproven AI visibility tools and experimental “GEO” tactics, while underfunding the proven fundamentals of content, SEO, and brand building. This is the wrong response to budget pressure. It is a bet on the uncertain future at the expense of the reliable present.
The framework below is designed to correct this inversion.
The 80/15/5 allocation rule
Instead of creating a new, isolated budget for AI optimization, we propose allocating your existing search marketing resources strategically based on the 80/15/5 Rule. This allocation is not arbitrary; it is grounded in the data presented throughout this report.
- 80% – Overlapping Fundamentals: The vast majority of your effort and investment should be focused on activities that are highly effective for both traditional SEO and AI visibility. This is justified by the expert consensus—from Danny Sullivan at Google to independent analysts like those at Onely—that SEO fundamentals (quality content, E-E-A-T, technical optimization) are the bedrock of AI visibility. The Chatoptic study showing 62% of top Google brands also appear in ChatGPT confirms that a strong SEO foundation is the most reliable path to AI visibility.
- 15% – Traditional SEO Specifics: A smaller portion of your budget should be reserved for the technical and tactical aspects of SEO that are less relevant to AI but still critical for driving traffic and revenue from Google Search, which still commands ~95% market share and drives 373x more searches than ChatGPT.
- 5% – AI-Specific Experimentation: A small, tightly controlled budget should be allocated for experimenting with the unique aspects of AI optimization. This is proportional to the 1.08% of referral traffic that AI chatbots currently drive. It allows for learning and adaptation without betting the farm on an unproven channel.
For the last few years, too many teams have moved their budget to something like a 70-10-20 or 60-10-30 split, spinning around in the hype feedback loop with little to nothing to show for it. If you fell prey to the FOMO trap, you can still easily get out without throwing more good money after bad.
The cost/benefit reality check: Why AI visibility tools are a bad investment
Before you allocate even 5% to AI experimentation, consider the cost/benefit analysis of the tools being sold to measure it. The pricing of AI visibility tools is staggeringly out of proportion to the value they provide.
| Tool Category | Example Tool | Monthly Cost | What’s Included |
|---|---|---|---|
| AI Visibility | Peec AI Starter | €89 (~$97) | 25 synthetic or user-defined prompts |
| AI Visibility | OtterlyAI Standard | $189 | 100 user-defined prompts |
| AI Visibility | Profound Growth for Brands | $399 | 100 prompts |
| Traditional SEO | Ahrefs Lite | $129 | 750 real keywords tracked |
| Traditional SEO | Semrush Toolkit Pro | $139.95 | 500 real keywords tracked |
| Email Marketing | Mailchimp Standard | $20 | 500 contacts |
| Social Media | Hootsuite Pro | $249 | 1 user, unlimited posts |
The math is damning. For the price of Profound Growth ($399/month) for a single brand, you could subscribe to Hootsuite, Mailchimp, and Ahrefs (or Semrush for $20 more). Those tools track real user behavior on proven channels that drive the overwhelming majority of your traffic and revenue. AI visibility tools track synthetic prompts on a channel that drives 1.08% of referral traffic.
The cost per tracked query is even more stark. Peec AI charges approximately $3.88, or €3.56, per prompt. Ahrefs charges approximately $0.20 per keyword. You are paying an 18x premium to track a guess about what users might ask, on a platform that sends a fraction of the traffic.
Our hands-on testing confirmed this poor value proposition even further: the data was inconsistent across metrics, and the technical issues make it even harder to trust the data to begin with. On top of that, the AI-generated guidance was so weak that you could likely get equally valid advice from asking ChatGPT questions like, “How do companies improve their share of voice?”
In other words, this is not a smart allocation of scarce marketing dollars. The 5% experimentation budget should be treated as R&D, not as a core investment. And if you do invest, use the cheapest tools available, or simply track your brand mentions manually.
The strategic pivot: from TOFU to BOFU
Before diving into the tactical allocation, it’s essential to understand where the real threat lies and where it doesn’t. The data from Seer Interactive and Semrush is clear: AI Overviews disproportionately impact TOFU informational queries.
In January 2025, 91.3% of queries triggering AI Overviews were informational. By October 2025, that share had dropped to 57.1%, but the pattern is clear: AI summaries are most effective at answering broad, definitional questions—the same queries that have always had the lowest conversion rates.
Meanwhile, BOFU content remains largely untouched. As Eyeful Media reports, “AI summaries often fall short here because they cannot replace the human element (product insights, real-world examples, etc.) that help someone choose between options.” BOFU keywords convert at an average rate of 4.85%, far higher than TOFU content.
The strategic implication is profound: don’t mourn lost TOFU traffic. That traffic was always low-value, high-volume, and difficult to attribute to revenue. Instead, double down on the middle and bottom of the funnel, where AI cannot easily replace human judgment, and where your content is most likely to drive actual business outcomes.
The 80%: What to invest in
This is the core of your strategy. These activities have the highest ROI because they serve both the current reality (Google dominance) and the potential future (increased AI usage).
- Create Best-in-Class, Human-Driven Content: This is the single most important investment. AI models are trained on the existing web. To be cited and trusted, your content must be original, insightful, and demonstrate true expertise. This means investing in real experts, original research, and unique points of view. The goal is to be the primary source material that both humans and AI turn to.
- Obsess Over User Intent: Go beyond keywords to understand the underlying questions, problems, and pain points of your audience. Create content that provides comprehensive, satisfying answers. This is what both Google’s ranking algorithms and AI answer engines are designed to reward.
- Aggressively Build E-E-A-T: Demonstrate your Experience, Expertise, Authoritativeness, and Trustworthiness in everything you do. This includes author bios, case studies, testimonials, third-party reviews, and associations with reputable organizations. These signals are crucial for both Google and for an AI trying to determine the reliability of a source.
- Strengthen Your Brand: As direct attribution becomes more difficult, a strong brand becomes your most valuable asset. Invest in brand marketing, PR, and social media to increase brand search volume and direct traffic. These are key metrics for demonstrating the impact of your efforts in a “dark funnel” world.
- Implement Robust Structured Data: Use Schema.org markup to clearly label the entities, facts, and relationships within your content. This makes it easier for machines (both Google and AI) to understand and accurately represent your information.
The 15%: Don’t abandon what works
Google still drives over 95% of search traffic. It would be unwise to ignore the specific tactics that are critical for success there.
- Technical SEO: Continue to invest in site speed, mobile-friendliness, crawlability, and indexation. These remain foundational for any search success.
- Link Building: While still important for direct AI citations, a strong backlink profile remains a primary ranking factor for Google and a powerful signal of authority.
- Local SEO: For businesses with physical locations, optimizing your Google Business Profile and local citations is still a no-brainer.
The 5%: Experiment and learn
This is your learning budget. It should be treated as R&D, with the expectation that most experiments will not yield a direct return but will provide valuable insights.
- Track a Small Set of Core Prompts: Use a low-cost tool (or even manual tracking) to monitor how your brand appears for a handful of your most important commercial-intent prompts. Don’t chase vanity metrics; look for actionable insights.
- Optimize for Citations and Quotability: Experiment with formatting content to be more easily quotable. Include clear, concise definitions, statistics, and expert quotes that are easy for an LLM to lift.
- Test New Content Formats: Experiment with creating content that directly answers conversational queries, such as comparisons, how-tos, and listicles that are structured for AI consumption. (Although again, you should have already been doing these for Google search, anyway.)
- Monitor AI Overviews on Your Core Queries: Use tools like Semrush or Ahrefs to track which of your target keywords are triggering AI Overviews. If your TOFU content is being cannibalized, consider whether that content was ever driving meaningful business outcomes in the first place.
By adopting this framework, you are building a marketing strategy that is robust and future-proof. You are investing in the durable assets of brand and expertise, which will only become more valuable in a world of ephemeral AI-generated content. You are protecting your budget from the hype and focusing your resources on what has been proven to work.
Conclusion: Breaking the cycle
This investigation began with a simple premise: to scrutinize the claims of the burgeoning AI search optimization industry. The findings are clear and consistent: the narrative of Google’s demise is a myth, the traffic from AI is negligible, and the tools being sold to capture this traffic are built on a foundation of flawed and opaque data.
This ecosystem is not the result of a grand conspiracy. It is the natural, predictable outcome of a system where financial incentives, technological hype, and human psychology have aligned to create a powerful feedback loop. It is an ecosystem that profits from fear and sells the illusion of control.
As a marketing leader, you have a choice. You can continue to operate within this hype cycle, chasing vanity metrics from unreliable tools and diverting precious resources to an unproven channel. Or, you can choose to break the cycle by:
- Demanding Evidence: Questioning the source and methodology of every metric you are shown.
- Trusting the Data: Prioritizing the hard data from your own analytics over the soft narratives of vendor marketing.
- Investing in Fundamentals: Recognizing that the most effective “AI strategy” is to be the most authoritative, helpful, and trustworthy resource in your field.
- Resisting FOMO: Having the discipline to distinguish between a genuine paradigm shift and a moral panic.
The future of search will undoubtedly involve AI. But the path to success in that future is not paved with new acronyms and expensive, black-box tools. It is paved with the same stones that have always led to success in search: a deep understanding of your customer, a commitment to quality, and the creation of genuine value. The brands that focus on these timeless principles will be the ones that thrive, long after the trough of disillusionment has washed the hype away.
Report methodology and time limitations
The purpose of this research was to determine whether AI visibility tool outputs correspond to what can be directly observed in major LLMs. Reported outputs were reviewed for consistency, alignment with observed model behavior, and coherence across systems.
All LLM queries were issued in a fresh incognito session to avoid personalization bias and maintain consistent testing conditions. All tool queries were conducted using a verified company‑domain account to maintain a consistent organizational identity across platforms.
This report is a snapshot in time, based on data available as of January 2026. Certain industry-level changes could materially alter the conclusions and recommendations in this report, including:
- AI Referral Traffic Share: A sustained increase in AI-driven referral traffic (exceeding 5%) would meaningfully change the calculus.
- LLM Query Data Access: If OpenAI, Google, or Anthropic provide marketers with anonymized query data, the synthetic data constraint could be substantially reduced or removed.
- Standardized Measurement: The development of an industry-wide auditable methodology for AI visibility could notably increase the reliability of third-party measurement tools.
- Search Market Composition: If Google’s market share declines in a material way, the current 80/15/5 allocation should be revisited.